
Generalization and ML Models:
在這章提到之前的問題,當訓練之後Loss最小,Accuracy最高時為甚麼model 在predict unseen data時總是成果不太好?原因是因為overfitting!
overfiting之前提到過,也就是你可以想像你原本在做一個linear regression的問題,當model成功fit你的data point時再加入其他沒看過的data point,此時如果你的model是memorize your training data set, 也就是你的model是記住了考古題的答案的感覺!這樣他們在新的data表現就會很差.
那究竟如何減少overfiting? ---> 使用validation set!
當你今天擁有收集好的data後,把你的data先分成 training set 跟 validation set, 有點像是我們在準備學測阿~ 把歷屆考題拿出來可能100~106年當作訓練, 然後107,108當作測試實力的題目這樣, 這樣可以知道自己在沒看過考題的狀況下到底學到了沒有. 概念就是如此. 然後當今天發現你在training set 上表現很好, validation set 上也表現很好那就知道 prediction 結果可能不錯. 但是有一個問題! 那我們怎麼知道甚麼時候該結束訓練以避免overfiting呢? 很簡單,一般來說training set 和validation set 的結果差不多時就該停止,當validation set 的誤差開始變大,那就是你overfit training set 的時候.
這時候就是該停止訓練的時機點了.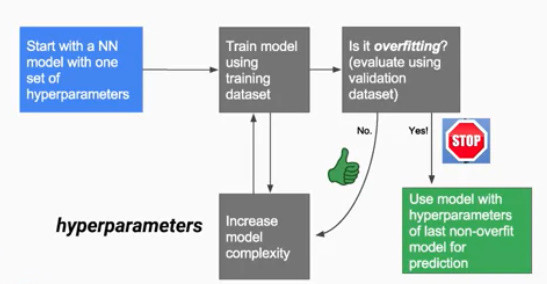
然而這樣還不足,因為validation set 是你在training過程中驗證的set,你的model會根據validation的output來調整訓練,也就是說你的model已經看過他了,因此validation的結果並不一定等於真的實際看沒看過的data的結果.與就是說經過100~106的考題你準備考試,接著根據107,108的考題,你開始調整讀書的方式補強不足的地方,然而這些都不代表你在109年考試一定會很好!也就是說109年的才是真正的test,使用validation只是在真正test之前先訓練的步驟之一. 因此你還需要testing set 來當真正應用的最後關卡.
如此一來更顯得data的重要性, 但是今天如果data不夠,你也可以採取cross validation的方式,也就是說把training set 和 validation set 拆成很多份,分別去做訓練,每次訓練都隨機用不同批,這樣你每次訓練看到的data都不同一批,如此一來就不怕會overfit特定批的資料. 這樣可以用較少量的data來達成訓練.
下次接著講如何來分批這些data!
